



AI Model Tuning and Optimization Services
AI model tuning and optimization services that improve accuracy, cut inference latency, and lower infrastructure cost. We fine-tune pre-trained models with LoRA, QLoRA, and RLHF for businesses across 20+ industries.
Are Your AI Models Underperforming in Production?
Most AI models lose accuracy after deployment. If that sounds familiar, you need ai model tuning and optimization services that ship measurable lift, not slide decks.
Model Accuracy Drops in Production
Models drift as real-world patterns change. AI model optimization services retrain and recalibrate to stay accurate.
Inference Is Too Slow For Real-Time
Slow models miss time-sensitive decisions. AI model tuning services tighten architectures for sub-second response times.
Infrastructure Costs Keep Growing
Large models burn GPU budget. AI model tuning and optimization services compress models and cut compute cost.
Generic Models Miss Your Domain
Generic models give generic results. LoRA fine-tuning adapts pre-trained models to your domain data quickly.
Test Wins, Production Failures
Production failures differ from lab results. AI model optimization services bridge that gap with production-grade tuning.
Edge Deployment Needs Smaller Models
IoT devices cannot run large models. AI model tuning services use quantization and distillation for edge.
Trusted AI/ML Model Performance at Scale
With 15+ years of experience, we have delivered 700+ projects across 20+ industries. Our ai model tuning and optimization services drive real, measurable improvements.
700+
Projects delivered successfully using 50+ technologies
700+
Projects delivered successfully using 50+ technologies
In-house experts with average 4+ years of experience
120+
120+
In-house experts with average 4+ years of experience
24Mn+
App store downloads with 96%+ crash-free users
24Mn+
App store downloads with 96%+ crash-free users
60%
Senior-level AI specialists on staff
60%
Senior-level AI specialists on staff
Happy clients and 60% recurring business
99%
99%
Happy clients and 60% recurring business
20+
Industries served across 25+ countries
20+
Industries served across 25+ countries
What Does Our AI Model Tuning and Optimization Services Engagement Cover?
Model Fine-Tuning
We adapt pre-trained models to your domain using LoRA and QLoRA parameter-efficient fine-tuning, lifting accuracy on your data without the full-fine-tune compute bill.
Domain-Specific Training:
We retrain models on your proprietary data to improve predictions that are directly relevant to your industry and workflows.
Transfer Learning:
We accelerate development by fine-tuning existing pre-trained models instead of training from scratch, saving time and compute.
Hyperparameter Optimization:
We systematically tune learning rates, batch sizes, and architectures to find the configuration that maximizes model accuracy.
Few-Shot Fine-Tuning:
We adapt models to new tasks with minimal labeled data, ideal when you have limited training examples available.
Model Optimization
We compress, quantize (int8 / fp16), distill, and prune models for faster inference and lower GPU cost, with deployment paths for cloud, mobile, and edge hardware.
Model Compression:
We reduce model size by up to 90% using pruning and distillation techniques while maintaining production-level accuracy.
Quantization:
We convert models from 32-bit to 8-bit precision for faster inference on CPUs and edge devices without significant accuracy loss.
Latency Optimization:
We optimize inference pipelines to achieve sub-second response times required for real-time applications and user interactions.
Cost Reduction:
We reduce GPU compute requirements by up to 60% through architecture optimization and efficient batch processing strategies.
NLP Model Fine-Tuning
We fine-tune language models with supervised tuning, RLHF, and instruction tuning for sentiment, classification, chatbots, and custom NLP, using ai model tuning services your team can ship.
Sentiment Analysis Tuning:
We calibrate NLP models to detect customer mood and opinion accurately across your specific domain and language style.
Text Classification:
We train models to categorize documents, emails, and support tickets into the right categories for your workflows.
Chatbot Response Quality:
We fine-tune conversational models to give more accurate, contextual, and brand-appropriate responses to user queries.
Named Entity Recognition:
We optimize NER models to extract specific entities like products, dates, and amounts from your business documents.
Computer Vision Optimization
We optimize image and video models for faster object detection, segmentation, and OCR, with quantized variants ready for edge and on-device inference.
Object Detection Tuning:
We calibrate detection models for your specific objects, environments, and quality requirements for production accuracy.
Image Classification:
We fine-tune classification models on your visual data to distinguish between categories specific to your business needs.
Edge Deployment:
We optimize computer vision models for mobile devices, cameras, and IoT sensors with minimal accuracy tradeoff.
Video Processing Speed:
We optimize frame-by-frame analysis to achieve real-time video processing speeds for security and monitoring applications.
Predictive Model Optimization
We improve accuracy and speed of forecasting models for demand planning, fraud and risk assessment, and revenue prediction across high-volume time series.
Forecast Accuracy Improvement:
We tune prediction models to achieve up to 85% higher accuracy compared to baseline, using ensemble and boosting techniques.
Real-Time Prediction:
We optimize models for instant predictions, enabling real-time scoring and decision-making in production environments.
Feature Engineering:
We identify and engineer the most predictive features from your data to improve model performance significantly.
Model Ensemble Strategies:
We combine multiple models to produce more reliable and accurate predictions than any single model alone.
Recommender System Tuning
We fine-tune recommendation engines for higher engagement, conversion lift, and relevance, with cold-start handling and bias-aware ranking baked in.
Collaborative Filtering Tuning:
We optimize similarity algorithms to improve recommendation relevance based on user behavior patterns.
Content-Based Optimization:
We tune content matching models to deliver more accurate suggestions based on item attributes and user preferences.
Real-Time Recommendations:
We optimize engines for instant recommendations that update as users interact with your platform in real time.
Cold Start Solutions:
We implement strategies for recommending to new users who have no interaction history yet on your platform.
What Does Our AI Model Tuning and Optimization Services Engagement Cover?
We deliver fine-tuning, RLHF, quantization, and distillation across model families like LLaMA, Mistral, GPT, and Falcon, lifting accuracy, latency, and cost-efficiency.
Model Fine-Tuning
We adapt pre-trained models to your domain using LoRA and QLoRA parameter-efficient fine-tuning, lifting accuracy on your data without the full-fine-tune compute bill.
Domain-Specific Training:
We retrain models on your proprietary data to improve predictions that are directly relevant to your industry and workflows.
Transfer Learning:
We accelerate development by fine-tuning existing pre-trained models instead of training from scratch, saving time and compute.
Hyperparameter Optimization:
We systematically tune learning rates, batch sizes, and architectures to find the configuration that maximizes model accuracy.
Few-Shot Fine-Tuning:
We adapt models to new tasks with minimal labeled data, ideal when you have limited training examples available.
Model Optimization
We compress, quantize (int8 / fp16), distill, and prune models for faster inference and lower GPU cost, with deployment paths for cloud, mobile, and edge hardware.
Model Compression:
We reduce model size by up to 90% using pruning and distillation techniques while maintaining production-level accuracy.
Quantization:
We convert models from 32-bit to 8-bit precision for faster inference on CPUs and edge devices without significant accuracy loss.
Latency Optimization:
We optimize inference pipelines to achieve sub-second response times required for real-time applications and user interactions.
Cost Reduction:
We reduce GPU compute requirements by up to 60% through architecture optimization and efficient batch processing strategies.
NLP Model Fine-Tuning
We fine-tune language models with supervised tuning, RLHF, and instruction tuning for sentiment, classification, chatbots, and custom NLP, using ai model tuning services your team can ship.
Sentiment Analysis Tuning:
We calibrate NLP models to detect customer mood and opinion accurately across your specific domain and language style.
Text Classification:
We train models to categorize documents, emails, and support tickets into the right categories for your workflows.
Chatbot Response Quality:
We fine-tune conversational models to give more accurate, contextual, and brand-appropriate responses to user queries.
Named Entity Recognition:
We optimize NER models to extract specific entities like products, dates, and amounts from your business documents.
Computer Vision Optimization
We optimize image and video models for faster object detection, segmentation, and OCR, with quantized variants ready for edge and on-device inference.
Object Detection Tuning:
We calibrate detection models for your specific objects, environments, and quality requirements for production accuracy.
Image Classification:
We fine-tune classification models on your visual data to distinguish between categories specific to your business needs.
Edge Deployment:
We optimize computer vision models for mobile devices, cameras, and IoT sensors with minimal accuracy tradeoff.
Video Processing Speed:
We optimize frame-by-frame analysis to achieve real-time video processing speeds for security and monitoring applications.
Predictive Model Optimization
We improve accuracy and speed of forecasting models for demand planning, fraud and risk assessment, and revenue prediction across high-volume time series.
Forecast Accuracy Improvement:
We tune prediction models to achieve up to 85% higher accuracy compared to baseline, using ensemble and boosting techniques.
Real-Time Prediction:
We optimize models for instant predictions, enabling real-time scoring and decision-making in production environments.
Feature Engineering:
We identify and engineer the most predictive features from your data to improve model performance significantly.
Model Ensemble Strategies:
We combine multiple models to produce more reliable and accurate predictions than any single model alone.
Recommender System Tuning
We fine-tune recommendation engines for higher engagement, conversion lift, and relevance, with cold-start handling and bias-aware ranking baked in.
Collaborative Filtering Tuning:
We optimize similarity algorithms to improve recommendation relevance based on user behavior patterns.
Content-Based Optimization:
We tune content matching models to deliver more accurate suggestions based on item attributes and user preferences.
Real-Time Recommendations:
We optimize engines for instant recommendations that update as users interact with your platform in real time.
Cold Start Solutions:
We implement strategies for recommending to new users who have no interaction history yet on your platform.
What Results Have Our Model Optimization Projects Delivered?
See how we have helped businesses improve AI accuracy and reduce inference costs through fine-tuning across LLaMA, Mistral, GPT, and Falcon models.
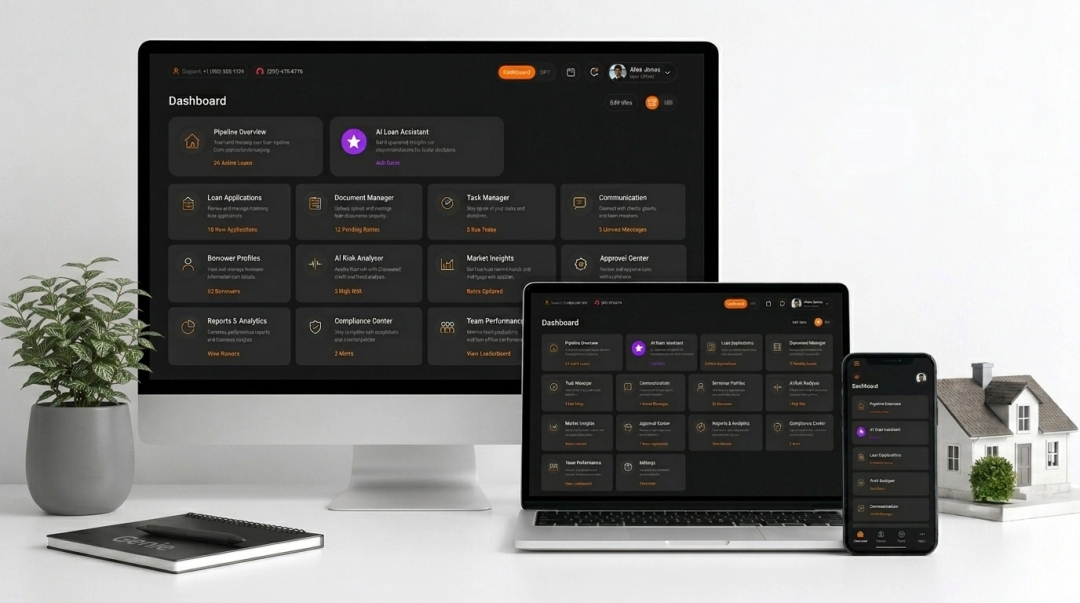

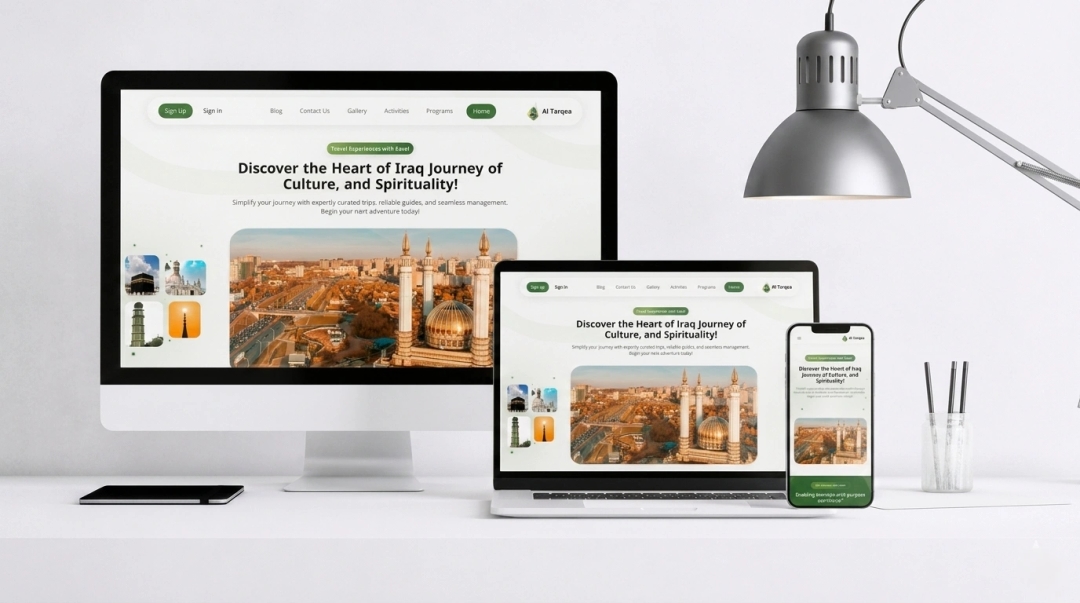





Which Tools and Frameworks Power Our Model Fine-Tuning?
We pair industry-leading ML frameworks with hardened MLOps tooling so every fine-tuning run is reproducible, observable, and shippable to any deployment target.
 Python
Python TensorFlow
TensorFlow PyTorch
PyTorch KerasPythonTensorFlowPyTorchKeras
KerasPythonTensorFlowPyTorchKerasWhich Industries Benefit from AI/ML Model Fine-Tuning?
Our model fine-tuning work improves AI performance across seven sectors with measurable lift on accuracy, latency, and cost. Here is where model optimization creates the biggest impact.
How Does Our Fine-Tuning and Optimization Process Work?
Our six-step approach delivers AI model training and optimization services that produce measurable, production-grade performance lift on every engagement.
Strategic Requirement Analysis
We analyze your model architecture, performance metrics, and business goals. We identify the specific areas where fine-tuning and optimization will deliver the biggest impact.
Data Curation & Preparation
We prepare high-quality training data for fine-tuning, including data cleaning, augmentation, and domain-specific labeling for your use case.
Benchmarking & Baseline Setup
We establish performance baselines and benchmark your current model against industry standards to measure improvement accurately.
Advanced Hyperparameter Tuning
We systematically optimize model parameters using grid search, random search, and Bayesian optimization techniques for maximum accuracy.
Iterative Retraining & Validation
We retrain models iteratively, validating against held-out test data to ensure improvements generalize to real-world scenarios.
Continuous Performance Monitoring
Post-deployment, we monitor model accuracy, latency, and drift. We retrain when performance degrades to maintain optimal results.
Our commitment to innovation and quality hasn't gone unnoticed. We are proud to be consistently recognized by leading industry bodies for our technical expertise, project success, and company culture. These accolades are a testament to the talent of our team and the trust of our partners.

Top Custom Software Development Company in India 2024

Top Mobile App Development Company in India 2024

Top ReactJs Company in India 2024

Top Website Developer 2023

Top Web Development Company in 2022

Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Custom Software Development Company in India 2024
Top Mobile App Development Company in India 2024
Top ReactJs Company in India 2024
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
What Are Clients Saying About Our Work?
Hear from businesses that lifted accuracy, cut latency, and shipped tuned models to production with our ML engineering team.








WANT TO TURN A GOOD MODEL INTO A GREAT ONE?
Fine-tuning is the difference between an AI model that works and one that wins. Our ML engineers turn underperforming models into production-grade assets that ship.
Key Benefits of AI Model Tuning and Optimization Services
The advantage of ai model tuning and optimization services is measurable lift across accuracy, latency, and cost. Here is what you gain when you ship with our team.
Improves Accuracy by Up to 40%
Lifts prediction accuracy 40% with LoRA fine-tuning on your proprietary data. This is especially valuable for ML leads protecting model SLAs.
Reduces Inference Latency for Real-Time
Cuts inference latency 70% with architecture optimization and quantization. This is especially valuable for product teams with sub-second SLOs.
Cuts AI Infrastructure Costs Up to 60%
Cuts GPU infrastructure cost 60% through compression, quantization, and efficient batching. This is especially valuable for FinOps leads cutting cloud spend.
Extends Model Lifespan With Continuous Retraining
Doubles model useful life with continuous retraining as data patterns evolve. This is especially valuable for data science leaders managing model fleets.
Enables Edge Deployment at Real Scale
Our AI and LLM optimization services compress models 90% for mobile, IoT, and edge. This is especially valuable for hardware-constrained product teams.
WANT TO TUNE, DEPLOY, AND WIN?
120+ AI-Powered Engineers | 15+ Years of Experience | 700+ Clients Transformed
Senior ML engineers. Production-grade tuning. Audit-ready. Free first consult.


How Do We Keep Your Tuned Models Performing in Production?
Going live is just the start. We work in your timezone post-launch, monitoring drift and retuning models so peak performance holds as data evolves.
Continuous Performance Monitoring
We track model accuracy, latency, and drift daily, spotting issues before they impact your business decisions.
Ongoing Model Retraining
We retrain and recalibrate models with fresh inputs as data evolves, keeping predictions sharp and AI relevant.
Infrastructure Optimization
We continuously optimize your compute resources and inference pipelines to reduce costs while maintaining or improving model performance.
Dedicated Support Team
Direct access to the ML engineers who optimised your models. No queues. Real experts, always.
READY TO MAXIMIZE YOUR AI MODEL PERFORMANCE?
Start with a free Model Performance Audit, then get fine-tuning that improves accuracy, lowers cost, and accelerates inference.
Frequently Asked Questions
Got questions about ai model tuning and optimization services? Here are the most common ones we hear from US and global ML teams.
44 reviews on Clutch
Got an idea? Let’s talk!
We turn bold ideas into shipped AI products that connect with users. Each concept gets a model audit, a tuning prototype, and a delivery plan.
Trusted by 3500+ Brand Worldwide










